Context is a search problem
Even frontier models fail without the right context. As models have gotten better at reasoning, the constraint on agent quality has shifted. It's no longer "can the model reason about this?" but "can it find the evidence it needs to reason at all?". Getting noisy results can derail the whole trajectory and produce wrong answers with high confidence, making search a critical component of agentic systems.
How agents retrieve information
In practice, there are two main approaches:
-
Naive RAG. Embed the query, run a vector or hybrid search, maybe rerank, and put the results into context. This is fast, cheap, and scales well through various vector databases. The problem is that it misses important details. A single embedding is a summary, and summaries lose exactly the low-level details that agent queries rely on.
-
Agentic / CLI harness. Give the agent filesystem access,
ls,glob,greptools, and the ability to read documents directly. This is what a lot of agent harnesses do today, as it produces higher-quality answers than naive RAG. However, the quality comes at a huge latency and cost premium. The agent spends a lot of tokens on serial tool calls and reading potentially unhelpful documents to find the information it needs. The cost also scales linearly with the number of documents, making this approach impractical for large datasets.
Why vector search fails for agents
Current vector search approaches are predominantly based on dense embeddings. The problem is that these embeddings are lossy summaries of the input document compressed into O(1k)-dimensional vector space. They capture broad, semantic information about the document, but lose the low-level details required to answer precise, long-tail queries.
Capturing high-level semantic information is perfectly fine for humans as they tend to issue broad, topical queries. Agents, on the other hand, tend to issue many precise queries in parallel, often trying different angles on the same topic. This produces a lot of overlapping results, leading to context bloat, without properly reflecting the agent's intent for each query. Unfortunately, the lack of representational capacity is not an engineering challenge, but a fundamental limitation of dense vector embeddings as proved in this paper.
How multi-vector fixes it
Multi-vector search, also known as late interaction, changes the representation from one vector per document to one vector per token in the document. This allows it to keep the low-level details uncompressed, while also capturing the high-level semantic information of the document. Document-query scores are computed at token granularity using the MaxSim (Chamfer similarity) operator - for each query token, it finds the most similar document token, and then sums the maximum similarity scores for all query tokens to produce a scalar score for the entire document.
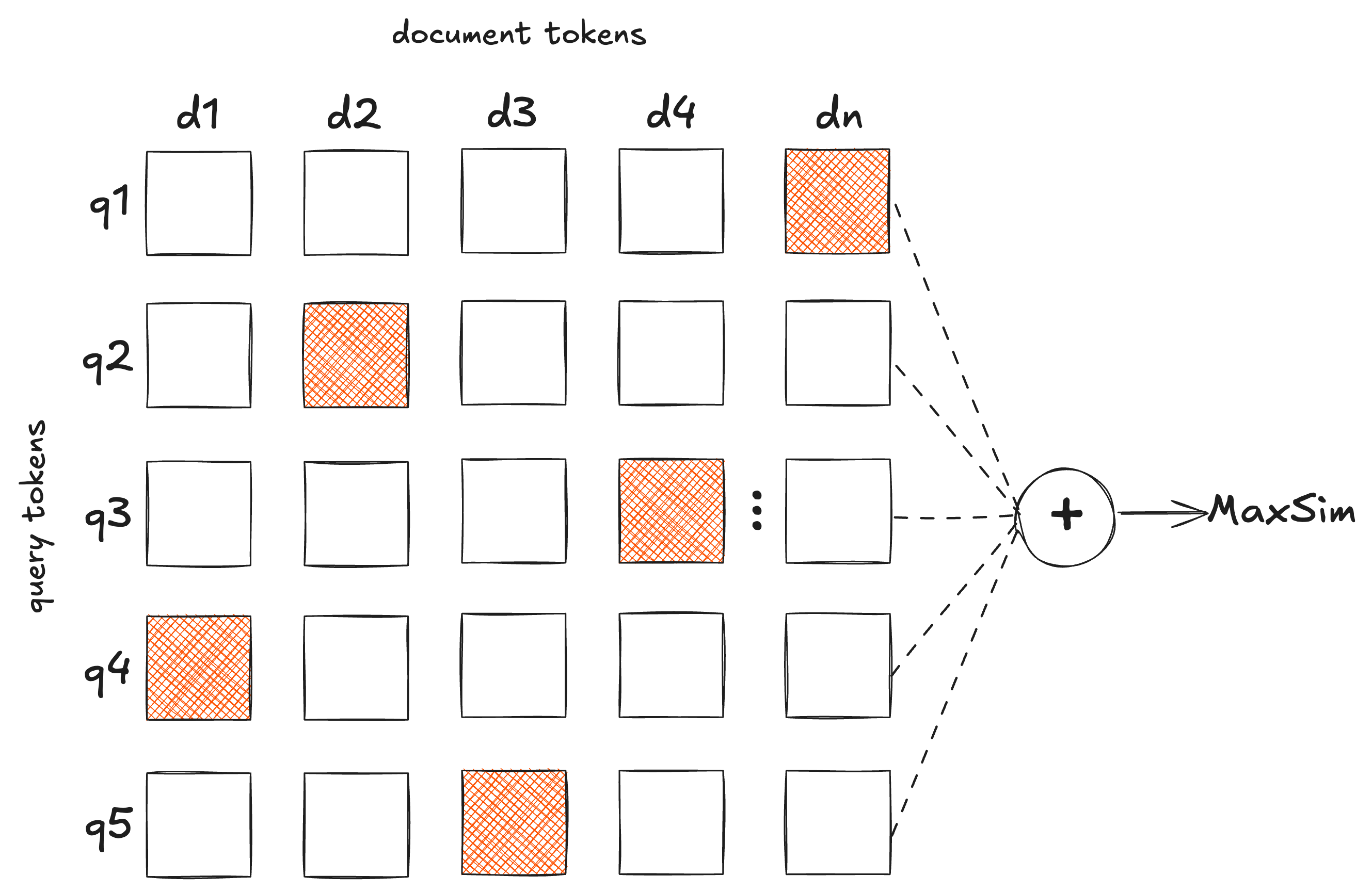
Free lunch?
The representational capacity of multi-vector embeddings and scoring expressiveness of MaxSim comes at a cost:
- Token-level embeddings require 10-100x more storage per document compared to dense embeddings.
- MaxSim scoring is computationally expensive, requiring ~2000x more compute than a single dot product.
The storage and compute overhead makes exhaustive multi-vector search impractical at even relatively small scale. Similar to single-vector search, approximate methods to scale multi-vector retrieval exist, for example PLAID or WARP. Generally, they rely on pre-computed indexes and heavy compression making online updates, deletes, filtering, and other production features difficult or impossible without costly index rebuilds. This is largely the reason why multi-vector search is not widely adopted outside the IR research community.
Multi-vector search in production
Okay, so now that we know why multi-vector search is the way to go, how do we actually run it in production?
SMVE: The algorithm
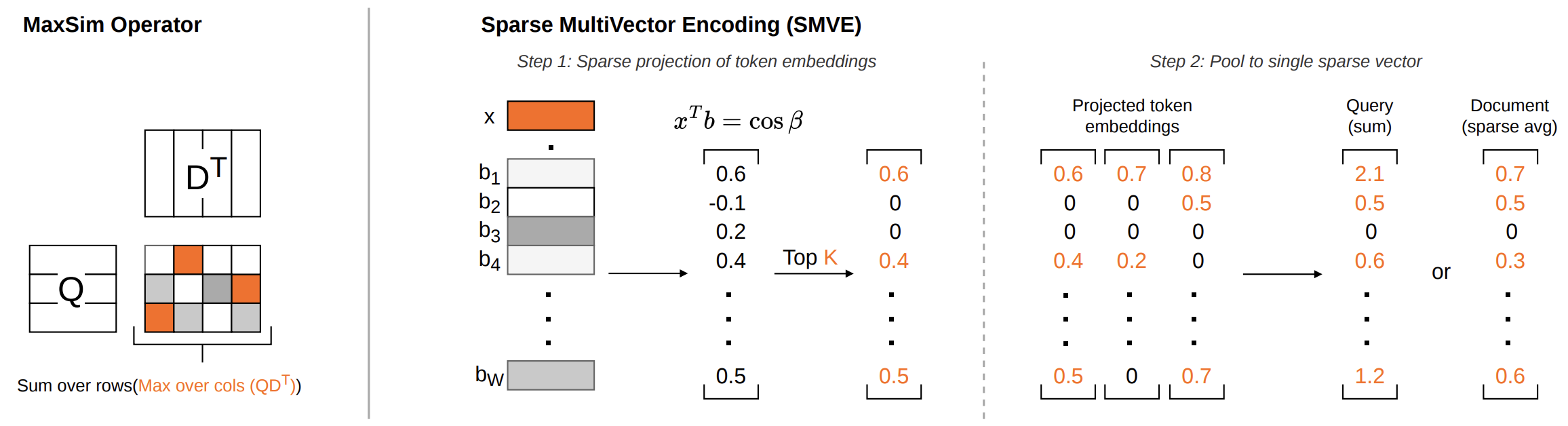
Our answer is Sparse Multi-Vector Encoding (SMVE). The core idea is to convert multi-vector document/query embeddings into sparse vectors so that their sparse dot product approximates MaxSim. Because storage and compute scale with the number of non-zero elements rather than the ambient dimensionality, SMVE produces expressive representations while remaining storage efficient and fast to query. If you want to learn more, you can read our blog where we describe the algorithm in more detail.
TopK: Scalable retrieval engine
SMVE is a fast first stage retriever. It allows us to prune billions of documents down to a handful of promising candidates with sub-100ms p99 latency. This ensures recall, but we still need to refine the candidates with full MaxSim to produce the final results with correct ranking. Combined, you get the recall and ranking of exhaustive MaxSim at orders of magnitude lower cost.
As we've seen with prior approaches, having fast scoring is not enough for production use cases. Efficient embedding inference, document quantization, filtering, online updates and deletes, and multi-tenancy are all required for real deployments. TopK handles all of these out of the box and abstracts the underlying complexity through multi_vector_index and semantic_index.
Results
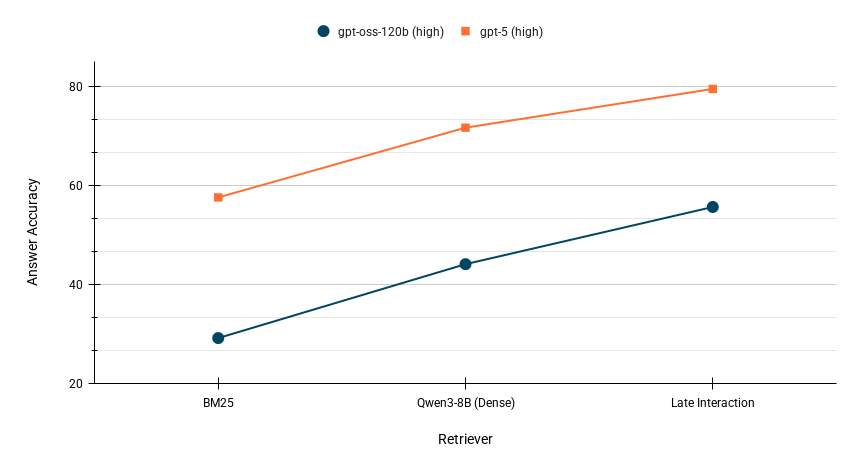
BrowseComp-Plus (deep research)
BrowseComp-Plus evaluates deep research agents against a fixed, human-verified corpus, which lets you isolate the retriever's contribution instead of hiding it behind a black-box web search. Swapping the retriever from BM25 to a dense model to late interaction lifts answer accuracy at every model size. Multi-vector search also enables smaller models, for example gpt-oss-120b, to achieve similar accuracy as much larger, proprietary, models with a weaker BM25 or single-vector dense retriever.
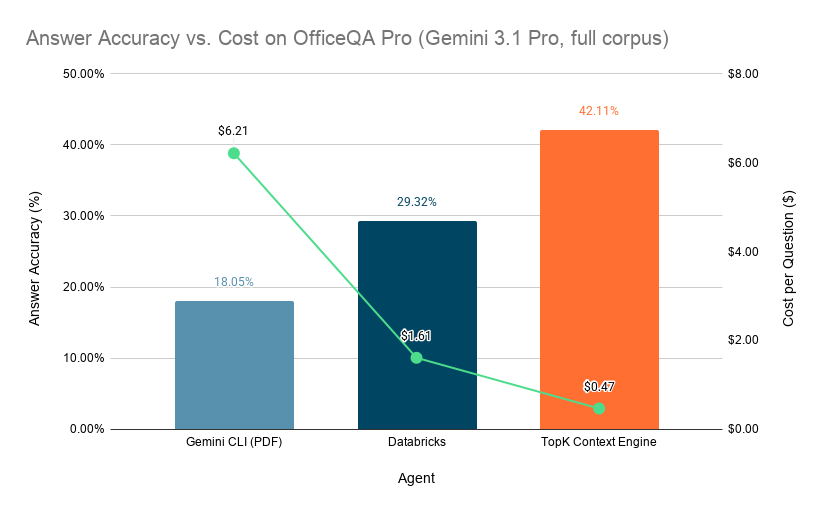
OfficeQA Pro (enterprise research)
OfficeQA Pro measures grounded reasoning over a messy, real-world enterprise corpus of complex documents with nested tables and long context dependencies. The baseline agent with CLI harness achieves only ~18% accuracy while consuming roughly $6.21 worth of tokens per query. Using the same model with late interaction retriever improves its accuracy about 2.3x to ~42% while cutting query costs by more than 10x to $0.47 per query.
Takeaways
Context is a search problem, and agent accuracy is bounded by retrieval quality. Single-vector embeddings have a theoretical ceiling that fine-tuning cannot lift, and the filesystem + tools fallback that teams often reach for is slow, expensive, and brittle at scale. Multi-vector (late interaction) is the retrieval primitive built to handle the long-tail, precise queries agents issue. SMVE makes it scale to billions of documents efficiently, and TopK makes it production-ready with online updates, filtering, multi-tenancy, and inference supported out of the box.