Late-interaction models are having a bit of a moment among the search community — and for good reason. They have been shown to be more expressive than single-vector retrieval across many benchmarks and modalities, but until recently they have been too expensive and cumbersome to use as a true first-stage retrieval primitive.
At TopK, we believe late-interaction retrieval deserves the same place in the search stack as established semantic retrieval primitives like single-vector embeddings and reranker models. Over the past few months, we have worked to make them a first-class feature of our database.
Multi-vector retrieval is now natively supported in TopK (docs), and in this post, we dive into how we made it scale to large datasets while preserving the CRUD properties of our database offering.
No free lunch with multi-vector retrieval
Multi-vector retrieval gets its quality from a richer scoring function: instead of compressing a query and document into one vector each and computing their dot product, it compares sets of token embeddings using the MaxSim operator, matching each query token against its most similar document token. That extra expressiveness is powerful, but not free. Compared to single-vector retrieval, you typically need to store far more data per document and do far more work at scoring time, which makes exhaustive multi-vector retrieval impractical at scale.
Prior work tackles this tradeoff in a few different ways: compress the token embeddings, keep fewer of them, build multi-stage retrieval pipelines such as PLAID, or collapse the multi-vector representation into one large descriptor as in MUVERA. MUVERA is especially interesting because it comes with theoretical guarantees: with sufficiently large descriptors, its scores approximate MaxSim closely enough to recover candidates similar to those from exhaustive late-interaction retrieval. The catch is that these descriptors need to be very large, which makes them expensive to store and compute with.
Our idea is simple: expressive descriptors may need to be large, but they do not need to be dense.
SMVE: Sparse Multi-Vector Encoding
SMVE is based on exactly that idea: instead of approximating multi-vector representations with dense descriptors, we convert them into sparse vectors whose dot product approximates MaxSim similarity.
Sparse vectors have a useful property: storage and computation depend only on the non-zero elements and effectively ignore everything else. This means that storage and computational complexity scale with the number of non-zero elements, not with the ambient dimensionality of the embedding space. That lets us build very high-dimensional representations that preserve much of the original expressiveness while remaining compact to store and fast to query.
The key question, then, is how to find a transformation that produces a sparse vector while still approximating MaxSim well.
How SMVE works
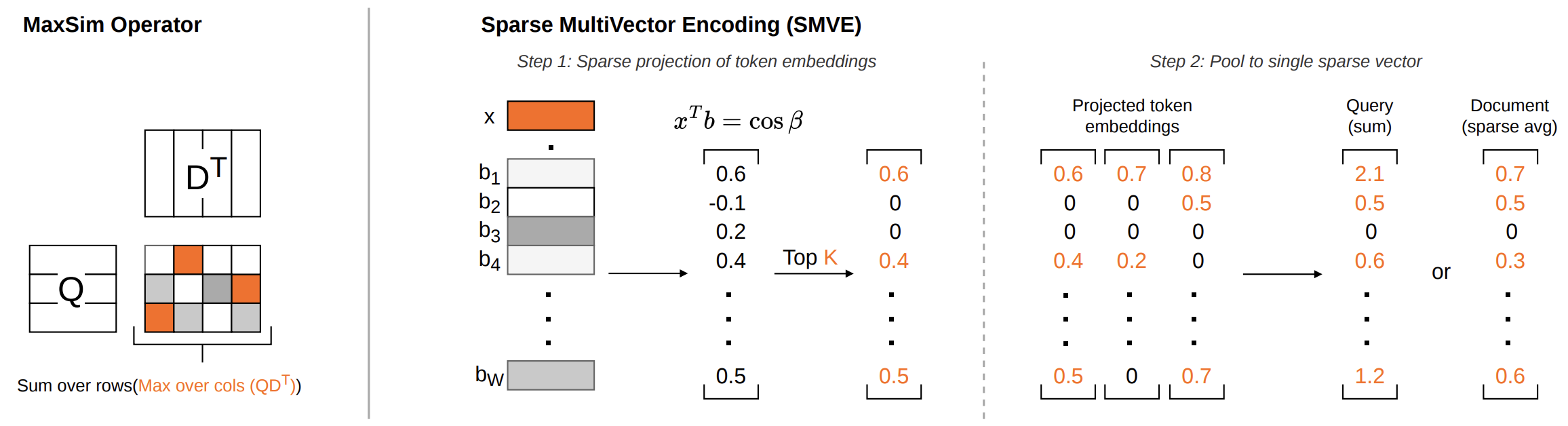
The answer is surprisingly simple - SMVE consists of just three steps:
- Random Projection onto Spherical Anchors: We sample a large set of random unit vectors that act as anchor directions in the embedding space. Each token embedding is then projected onto these anchors, producing a higher-dimensional vector of cosine similarities. Intuitively, this gives us a sketch of where the token sits relative to many reference directions.
- Sparsification: For each projected token vector, we keep only the Top-K largest values and set the rest to zero. This works well because in high-dimensional spaces, a vector tends to have very small inner products with most random directions, so most projection values stay close to zero while only a small number capture strong alignment with the anchor directions. Keeping only those strongest signals gives us a sparse representation of each token embedding.
- Pooling: Finally, we aggregate the token-level sparse representations into a single sparse vector. In particular, for queries we sum the token vectors, while for documents we average the non-zero contributions in each dimension.
Lastly, we can repeat the steps multiple times with different random matrices and concatenate the results to reduce variance and improve retrieval quality.
The core SMVE transformation is simple enough to express in just a few lines of code.
from torch import randn, Tensor, topk, zeros_likeembedding_dim = 128 # dimension of the input token embeddingswidth = 2048 # dimension of the SMVE-transformed embeddingsk = 8 # number of non-zero elements to keep for each token# sample a random matrix B with unit-norm columns# -> a large set of anchor directions spread across the unit sphereB = randn(embedding_dim, width) # shape (embedding_dim, width)B /= B.norm(dim=0, keepdim=True) # normalize each column to unit lengthdef smve(token_embeddings: Tensor, B: Tensor, k: int, is_query: bool) -> Tensor:# random projection: num_tokens x embedding_dim -> num_tokens x widthprojections = token_embeddings @ B# top-k sparsification: keep only the k largest values for each token# shape remains num_tokens x widthvalues, indices = topk(projections, k)sparse = zeros_like(projections)sparse.scatter(dim=-1, index=indices, src=values)# pooling: num_tokens x width -> width# for both queries and documents, we first sum the token vectorspooled = sparse.sum(dim=0)# nothing else to do for queriesif is_query:return pooled# for documents, we average the non-zero values in each dimension:# we compute the count of non-zero contributions in each dimension,# clamp to 1 to avoid division by zero,# and divide the sum-pooled vector by the count to get the averagenon_zero_counts = (sparse != 0).sum(dim=0).clamp(min=1)return pooled / non_zero_counts
Apart from the input embedding dimension set by the underlying late-interaction model, SMVE has only two hyperparameters: the number of anchor directions (width) and the number of non-zero values kept per token (k).
Importantly, storage and compute are controlled by k, not by width. Each token contributes at most k non-zero values, so a pooled embedding for an input with n tokens has at most k * n non-zero elements. In practice, query and document embeddings can be pruned even further.
TopK's production implementation uses optimized sparse representations and compute kernels to achieve the best possible performance when applying SMVE in both query and write paths.
Multi-vector retrieval with SMVE
We employ SMVE in the first stage of multi-vector retrieval in TopK. In particular, we store both the SMVE-transformed document representations and the original multi-vector representations.
At query time, we first retrieve a candidate set using fast sparse retrieval over the SMVE-transformed representations, possibly overfetching by a small constant factor to compensate for approximation error. This step benefits directly from sparsity: documents that do not overlap with the non-zero structure of the query can be filtered out very efficiently.
We then score the candidates using their original multi-vector representations and the full MaxSim operator. This two-step process allows us to essentially match the quality of exhaustive MaxSim retrieval while speeding up the process significantly.
Experimental results
We evaluated SMVE on several large-scale datasets from the BEIR benchmark using embeddings produced by ColBERTv2. Experiments were run on MS MARCO, Natural Questions (NQ), and HotpotQA, using a production implementation inside TopK.
Our experiments focused on the trade-off between latency and recall in the end-to-end late-interaction retrieval pipeline. Specifically, we measured end-to-end query latency, including query embedding, candidate retrieval using SMVE, and final reranking with MaxSim over quantized multi-vector representations. To verify that these efficiency gains do not come at the cost of retrieval quality, we also measured recall@k for the full retrieval pipeline.


Across all datasets, SMVE substantially reduces end-to-end latency while maintaining competitive retrieval quality. Compared to prior late-interaction systems such as PLAID and MUVERA, SMVE achieves roughly 5–8× lower latency at common retrieval cutoffs. For example, on MS MARCO, a dataset with 8.8 million documents, average query latency is 39.9 ms for k=100 and 60.3 ms for k=1000, compared to 221–318 ms for PLAID and 310–444 ms for MUVERA. Similar trends hold on NQ and HotpotQA, where SMVE consistently delivers the fastest response times.
Crucially, these latency improvements do not come at the cost of retrieval quality. Recall@k remains competitive with the strongest baselines across datasets. On MS MARCO and NQ, SMVE closely matches the recall of both PLAID and MUVERA, while on HotpotQA it significantly outperforms PLAID and remains close to MUVERA.
These results demonstrate that late-interaction retrieval can operate as a practical first-stage retrieval primitive on large datasets, achieving high recall with low end-to-end latency.
Production-ready setup with TopK
Our goal with this work was not just to make late-interaction retrieval faster in theory, but to make it practical to deploy in real systems.
SMVE gives us a straightforward path to production: instead of relying on specialized multi-stage pipelines, we can transform multi-vector representations into sparse embeddings at write time and query them efficiently using our scalable sparse retrieval infrastructure.
These ideas are now built directly into TopK, so you can use late-interaction models on large and dynamic corpora without assembling a complex retrieval stack. Simply ingest your representations and let TopK index and query them cost-effectively at scale.
Start with the multi-vector retrieval guide