State-of-the-art retrieval quality usually comes with a catch. You start with an embedding pipeline, a vector database, add hybrid search with RRF, and maybe a reranker. But production search systems don't live isolated inside notebooks. They are a distributed system with reliability and latency budgets, constant writes, strict freshness requirements, high-QPS reads, filters, permissions, and much more.
That's why we built semantic_index — a single schema annotation that abstracts this complexity and enables state-of-the-art retrieval ready for production. Batteries included.
from topk_sdk.schema import text, semantic_indexclient.collections().create("docs",schema={"text": text().index(semantic_index())})
That's the entire setup. No embedding pipeline, no separate vector store, no reranking service. Under the hood, semantic_index is powered by Iso-ModernColBERT (our multi-vector embedding model) and sparse multi-vector encoding (SMVE), which makes late interaction scale to billions of documents with filtering and online index updates.
Why multi-vector?
Single-vector (dense) embeddings compress an entire document into one point in high-dimensional space. That works until your queries get specific — for example, a clause in a contract, a row in a financial table, or a step in a procedure. Late interaction models keep one embedding per token and match at token granularity, which is why they consistently outperform dense models on out-of-domain and long context retrieval.
The problem was never quality; it was cost and operational complexity. Multi-vector indexes are an order of magnitude larger, and exact MaxSim scoring is computationally expensive. TopK solves this by identifying a small set of candidates using fast sparse approximations and then refining them to the final top-k results using quantized MaxSim reranking.
Performance
- Ingest 1.5B+ tokens/hour — embedded and indexed, with sub-second index lag. Your documents are searchable as you write them.
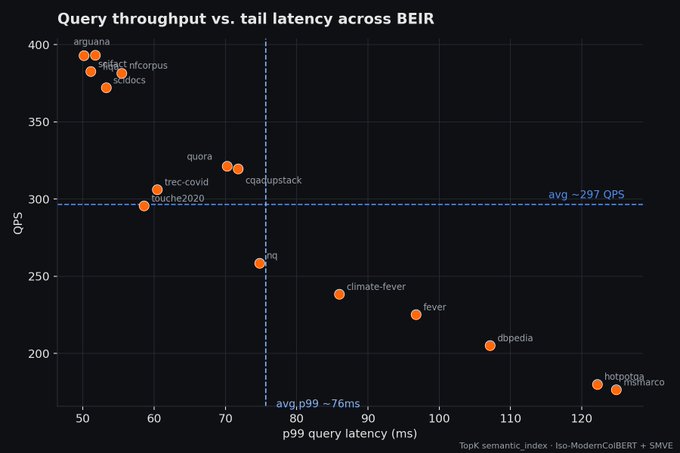
- 295 QPS across BEIR with ~75ms p99 latency — high-quality search without performance tradeoffs.
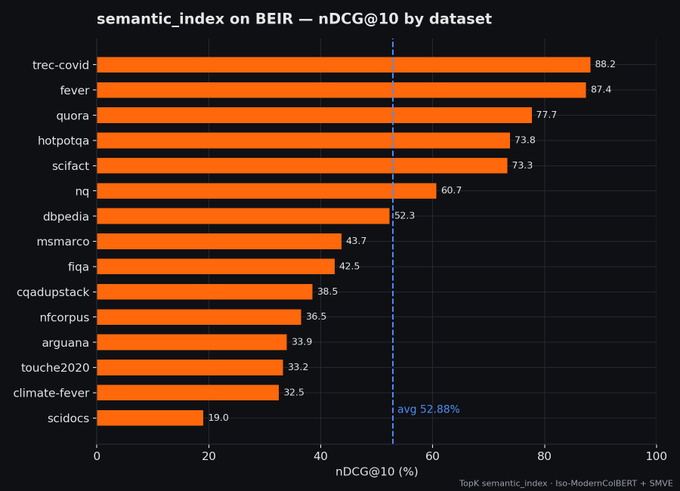
- 52.88% nDCG@10 on BEIR — end-to-end, on the live system, not an offline eval of the model alone.
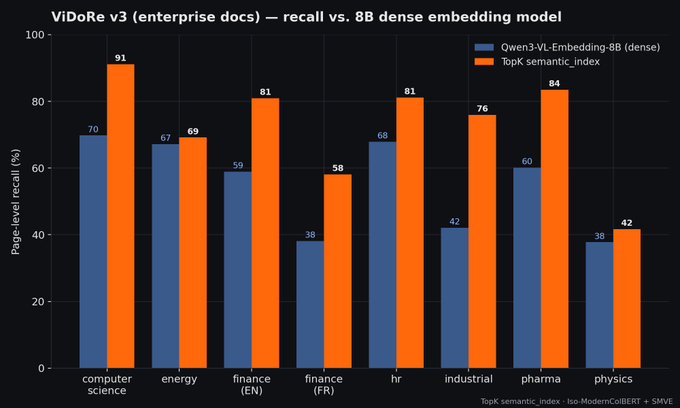
- ~30% higher recall and nDCG@10 on ViDoRe v3 — state-of-the-art performance beating 80x bigger Qwen3-VL-Embedding-8B model.
- 80.48% accuracy on BrowseComp-Plus — top-5 performing research agent without a complicated search pipeline.
BEIR: Baseline
Most retrieval benchmarks measure the model in isolation. We measured the whole system end-to-end — including document ingestion, embedding inference, indexing, and concurrent queries on our production clusters. Across all 15 BEIR datasets, semantic_index averages 52.88% nDCG@10, only ~1% lower than the base model with exact MaxSim.
On the performance side, every dataset cleared 175 QPS, smaller corpora pushed past 390 QPS, and p99 latency stayed between 50ms and 125ms with sub-second index lag throughout. Your documents are searchable as you write them, which is becoming increasingly more important for agentic use cases.
ViDoRe V3: Enterprise Retrieval
BEIR is text-only. Enterprise retrieval is complex PDFs, tables, slides, and multilingual documents, which is exactly where token-level matching pulls away from dense embeddings. We compared semantic_index against Qwen3-VL-Embedding-8B, a state-of-the-art dense embedding model 80x larger than ours.
+34% recall, +30% nDCG@10 improvement on average. On industrial documentation, recall jumps from 42.05% to 75.97% (+81%). Finance (EN) goes from 58.90% to 80.91%. Pharma from 60.16% to 83.52%. There isn't a single domain where the 8B dense model wins.
BrowseComp-Plus: Agentic Search
Retrieval is increasingly consumed by agents, not humans. We plugged semantic_index into an agentic research loop as the retriever for BrowseComp-Plus. A gpt-5 agent with the default harness achieved 80.48% accuracy and 77.82% recall, placing it top-5 in the overall leaderboard (as of June 11, 2026).
The agent averaged ~14 search calls per task with 88.54% citation precision, which indicates that the retriever is surfacing the right documents early enough for the agent to ground its answers without wasting tokens.
Try it today
Everything above — multi-vector embedding inference, retrieval with quantized MaxSim reranking, online index updates, and filtering — is available today behind simple, high-level abstractions.
from topk_sdk.schema import text, semantic_indexfrom topk_sdk.query import select, field, fn# Create collection with semantic_indexclient.collections().create("docs",schema={"text": text().index(semantic_index()),},)# Insert documentsclient.collection("docs").upsert([{"_id": "doc-1", "text": "..."},{"_id": "doc-2", "text": "..."},])# Query using maxsim scoring with semantic_similaritydocs = client.collection("docs").query(select("text",score=fn.semantic_similarity("text","query string"),).top_k(field("score"), 10))
- Get started: console.topk.io
- Docs: docs.topk.io/guides/semantic-search